01 Zookeeper 部分
- CAP定理
- ZAB协议
- leader选举算法和流程
加密,是以某种特殊的算法改变原有的信息数据,使得未授权的用户即使获得了已加密的信息,但因不知解密的方法,仍然无法了解信息的内容。大体上分为双向加密和单向加密,而双向加密又分为对称加密和非对称加密(有些资料将加密直接分为对称加密和非对称加密)。
双向加密大体意思就是明文加密后形成密文,可以通过算法还原成明文。而单向加密只是对信息进行了摘要计算,不能通过算法生成明文,单向加密从严格意思上说不能算是加密的一种,应该算是摘要算法吧。具体区分可以参考:
继续阅读Java中常用的加密方法(JDK)
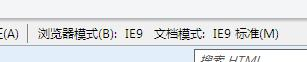
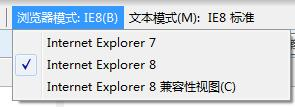
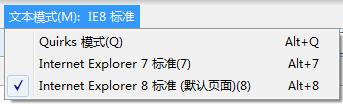
浏览器模式”和“文档模式”的区别 在IE8中按F12键,打开“开发人员工具”,在菜单栏中可以看到“浏览器模式”和“文档模式”的切换菜单,其中可以选择切换到IE6/7/8等不同的网页模式。那“浏览器模式”和“文档模式”之间有什么区别呢? “浏览器模式”用于切换IE针对该网页的默认文档模式、对不同版本浏览器的条件备注解析、发送给网站服务器的用户代理(User-Agent)字符串的值。网站可以根据浏览器返回的不同用户代理字符串判断浏览器的版本和安装的功能,这样就可以向不同的浏览器返回不同的页面内容。 默认情况下,IE8的浏览器模式为IE8。用户可以通过单击地址栏旁边的兼容性视图按钮( )来手动切换到不同的浏览器模式。在IE8中,IE8兼容性视图会以IE7文档模式来显示网页,同时会向服务器发送IE7的用户代理字符串。 “文档模式”用于指定IE的页面排版引擎(Trident)以哪个版本的方式来解析并渲染网页代码。切换文档模式会导致网页被刷新,但不会更改用户代理字符串中的版本号,也不会从服务器重新下载网页。切换浏览器模式的同时,浏览器也会自动切换到相应的文档模式。
9、CMake手册详解 (九)内容为else elseif enable_language enable_testing endforeach endfunction endif endmacro endwhile
execute_process export
10、file< 文件操作命令
16 、CMake 手册详解(十六)foreach function get_cmake_property get_directory_property get_filename_component
在一个千万级的数据库查寻中,如何提高查询效率?分别说出在数据库设计、SQL语句、java等层面的解决方案。
解答:
1)数据库设计方面:
a. 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
b. 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0
c. 并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
d. 索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
e. 应尽可能的避免更新索引数据列,因为索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新索引数据列,那么需要考虑是否应将该索引建为索引。
f. 尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
g. 尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
h. 尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
i. 避免频繁创建和删除临时表,以减少系统表资源的消耗。
j. 临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
k. 在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
l. 如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
2)SQL语句方面:
a. 应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
b. 应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20
c. in 和 not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了: select id from t where num between 1 and 3
d. 下面的查询也将导致全表扫描: select id from t where name like ‘%abc%’
e. 如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描: select id from t wherenum=@num 可以改为强制查询使用索引: select id from t with(index(索引名)) wherenum=@num
f. 应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2=100 应改为: select id from t where num=100*2
g. 应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where substring(name,1,3)=’abc’–name以abc开头的id select id from t where datediff(day,createdate,’2005-11-30′)=0–‘2005-11-30’生成的id 应改为: select id from t where name like ‘abc%’ select id from t where createdate>=’2005-11-30′ and createdate<‘2005-12-1’
h. 不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
i. 不要写一些没有意义的查询,如需要生成一个空表结构: select col1,col2 into #t from t where 1=0 这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样: create table #t(…)
j. 很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num)
k. 任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
l. 尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
m. 尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
n. 尽量避免大事务操作,提高系统并发能力。
3)java方面:
a.尽可能的少造对象。
b.合理摆正系统设计的位置。大量数据操作,和少量数据操作一定是分开的。大量的数据操作,肯定不是ORM框架搞定的。,
c.使用jDBC链接数据库操作数据
d.控制好内存,让数据流起来,而不是全部读到内存再处理,而是边读取边处理;
e.合理利用内存,有的数据要缓存
用Hibernate开发的应用,使用是Oracle10g,使用的方言是org.hibernate.dialect.OracleDialect
数据到达360W的时候,分页查询比较慢,达到10S多,分析了自动生成的SQL,发现SQL格式如下:
SELECT *
FROM (SELECT row_.*, ROWNUM rownum_
FROM (SELECT users.id,users.name
FROM my.users users0_) row_)
WHERE rownum_ <= 100 AND rownum_ > 10
将方言改为org.hibernate.dialect.Oracle10gDi生成的SQL是
SELECT *
FROM (SELECT row_.*, ROWNUM rownum_
FROM (SELECT users.id,users.name
FROM my.users users0_) row_ where rownum <= 100 )
WHERE rownum_ > 10。
速度很快。
1、高级查询与简单查询:如是列表中存在高级查询和简单查询时,简单查询一般只用一个文本框,以突出其简单快速的特性;高级查询应该采用链接的形式,以表明要转到另外一个页面,如baidu中的“高级”链接,google中的” 高级搜索”链接。
2、按钮的使用:系统中一般如果存在与数据库交互的应该使用按钮,如增加,修改,删除等。对于页面的跳转一般采用链接的形式。如转到增加页面。转修改页面等;
3、系统分析设计中尽量少用或不用“信息”,“管理”等字样,这些词一般概括性较强,但不具体,不适合用于这些场合
4、用例的名称一般采用动词+名词的形式命名
启动tomcat时一切貌似正常,但是就是不能访问应用。仔细查看catalina.out 发现No Default web.xml。在conf下查看,果然没有web.xml。复制一个web.xml再启动就好了,还不清楚为什么web.xml没有了。
1、序列化
Volatile transient http://www.blogjava.net/fhtdy2004/archive/2009/06/20/286112.html
2、Math API
http://hunter090730.iteye.com/blog/485770
public static void main(String args[]) {
System.out.println(“result:”+11+1);
System.out.println(“result:”+”12345”.valueOf(54321));
double d = -4.4999999;
System.out.println(Math.ceil(d));//不小于参数的最小整数值.
System.out.println(Math.floor(d));//不大于参数的最大整数值.
System.out.println(Math.round(d));//四舍五入法最接近参数的int/long值.
}
输出为:
result:111
result:54321
-4.0
-5.0
-4
3、Android的Message,MessageQueue,Looper,Handler详解+实例
http://blog.csdn.net/zhangren07/article/details/6400845
4、HashTable ,HashMap
5、Android 主要组件Activity, Service, ContextProvider, BroadcastReceiver
6、android:screenOrientation
SSH开发项目是目前十分流行的一个趋势。对于从事JavaEE项目开发多年的朋友来说,开发时使用SSH确实能带来不少的便利。SSH帮你做了一个规划,让你将不同的程序代码放到不同的地方。使整个工程看起来,更加工整,大家都采用这种模式开发程序,相互更容易沟通。新的成员也更容易融入到项目中。但对于刚入行的朋友来说,有点力不从心。有些朋友会说我只是实现一个很小的功能,为什么要写那么多的代码,建立那么多的类,还有一大堆的配置文件。出现一些问题还要花上半天去找原因,真是麻烦。所以在这里我想结合自己的体会、经历,对于初涉及到SSH项目的朋友,说说如何快速定位问题。
1、直接根据错误日志找到出错位置。(这种方法比较容易,大家常用的,不多说)
对一些不明错误(所谓不明错误是指编译没有问题,运行过程也不报错,但就是得不到预期的结果)用第一种方法是找不到原因的。要查找此类问题要根据SSH框架的结构,我们都知道: SSH框架是由三个框架有机组合而成的,它们分工明确,流水作业。从前台到后台,从Http请求到数据库,依次为Stucts->Spring->Hibernate。所以当出现错误时,我们可采用两种方法:
2、顺藤摸瓜:
从Stucts开始,看看是否能接收到正确的请求数据。如果正确,接着往下看看Spring中的业务操作是否正确,如果没有问题就接着往下找,到Hibernate层看看,操作数据库是否有问题。对于一般的问题通过这三个步骤都能找出问题的原因。但这种找原因方法破费太大了一些。对于那些隐蔽较好的错误。或者,开发者,过于疲劳没有思路时才如此全面检查。另外:这种方法对初涉及SSH项目的朋友比较有好处,多如此查找几次你就明白了SSH框架的运行机制。
3、大胆猜测,定点检查:
如果你从事SSH项目有一年半载了,对SSH比较熟悉了,并且对所做项目比较了解。遇到不明错误就可根据经验猜测什么地方出现了问题,就在那打上一个断点,或者多猜测几个位置,用一组测试数据测试,当运行到断点时,看看数据是否有异常。